Comparing splits using information theory
Martin R. Smith
Source:vignettes/information.Rmd
information.RmdTo understand the information-based metrics implemented in ‘TreeDist’, it is useful to recall some basic concepts of information theory.
For an introduction, see MacKay (2003) or an introductory video to the clustering information distance:

Splits
Each internal edge in a tree represents a split that divides its leaves into two partitions. Intuitively, some splits are more instructive than others. For example, the fact that mammals and reptiles represent two separate groups is profound enough that it is worth teaching to schoolchildren; much less information is represented by a split that identifies two species of bat as more closely related to one another than to any other mammal or reptile.
Quantifying information
How can we formalize the intuition that some splits contain more information than others? More generally, how can we quantify an amount of information?
Information is usually measured in bits. One bit is the
amount of information generated by tossing a fair coin: to record the
outcome of a coin toss, I must record either a H or a
T, and with each of the two symbols equally likely, there
is no way to compress the results of multiple tosses.
The Shannon (1948) information content of an outcome is defined to be , which simplifies to when all outcomes are equally likely. Thus, the outcome of a fair coin toss delivers of information; the outcome of rolling a fair six-sided die contains of information; and the outcome of selecting at random one of the 105 unrooted binary six-leaf trees is .
Unlikely outcomes are more surprising, and thus contain more
information than likely outcomes. The information content of rolling a
twelve on two fair six-sided dice is
,
whereas a seven, which could be produced by six of the 36 possible rolls
(1 & 6, 2 & 5, …), is less surprising,
and thus contains less information:
.
An additional 2.58 bits of information would be required to establish
which of the six possible rolls produced the seven.
Application to splits
The split
AB|CDEF is found in 15 of the 105 six-leaf trees; as such,
the probability that a randomly drawn tree contains
is
,
and the information content
.
Steel & Penny (2006) dub this quantity
the phylogenetic information content.
Likewise, the split
ABC|DEF occurs in nine of the 105 six-leaf trees, so
.
Three six-leaf trees contain both splits, so in combination the splits
deliver
of information.
Because , some of the information in is also present in . The information in common between and is . The information unique to and is .
These quantities can be calculated using functions in the ‘TreeTools’ package.
library("TreeTools", quietly = TRUE)
library("TreeDist")
treesMatchingSplit <- c(
AB.CDEF = TreesMatchingSplit(2, 4),
ABC.DEF = TreesMatchingSplit(3, 3)
)
treesMatchingSplit## AB.CDEF ABC.DEF
## 15 9
proportionMatchingSplit <- treesMatchingSplit / NUnrooted(6)
proportionMatchingSplit## AB.CDEF ABC.DEF
## 0.14285714 0.08571429
splitInformation <- -log2(proportionMatchingSplit)
splitInformation## AB.CDEF ABC.DEF
## 2.807355 3.544321
treesMatchingBoth <- TreesConsistentWithTwoSplits(6, 2, 3)
combinedInformation <- -log2(treesMatchingBoth / NUnrooted(6))
sharedInformation <- sum(splitInformation) - combinedInformation
sharedInformation## [1] 1.222392
# Or more concisely:
SplitSharedInformation(n = 6, 2, 3)## [1] 1.222392Entropy
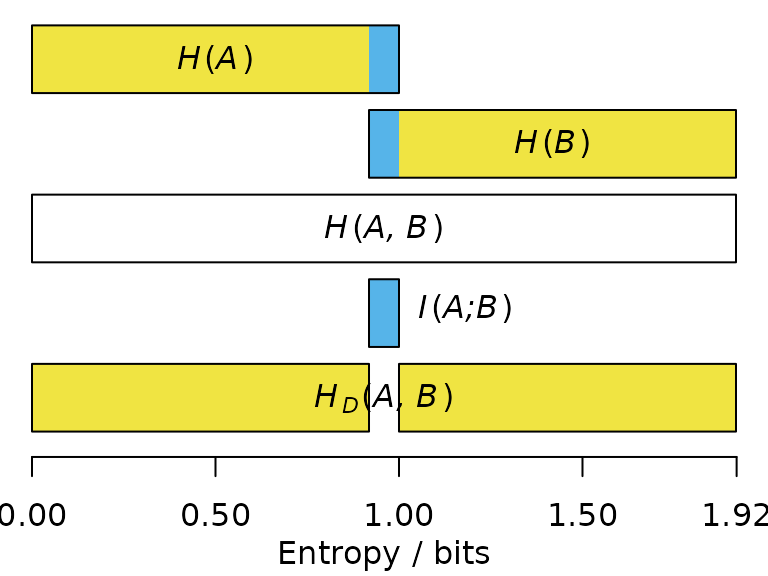
Entropy is the average information content of each outcome, weighted by its probability: . Where all outcomes are equiprobable, this simplifies to .
Consider a case in which Jane rolls a dice, and makes two true statements about the outcome :
: “Is the roll even?”.
- Two equally-possible outcomes: yes or no
- Entropy: .
: “Is the roll greater than 3?”
- Two equally-possible outcomes: yes or no
- Entropy: .
The joint entropy of and is the entropy of the association matrix that considers each possible outcome:
| odd | even | |
|---|---|---|
Note that this less than the we require to determine the exact value of the roll: knowledge of and is not guaranteed to be sufficient to unambiguously identify .
The mutual information between and describes how much knowledge of reduces our uncertainty in (or vice versa). So if we learn that is ‘even’, we become a little more confident that is ‘greater than three’.
The mutual information , denoted in blue below, corresponds to the sum of the individual entropies, minus the joint entropy:
If two statements have high mutual information, then once you have heard one statement, you already have a good idea what the outcome of the other statement will be, and thus learn little new on hearing it.
The entropy distance, also termed the variation of information (Meila, 2007), corresponds to the information that and do not have in common (denoted below in yellow):
The higher the entropy distance, the harder it is to predict the outcome of one statement from the other; the maximum entropy distance occurs when the two statements are entirely independent.
Application to splits
A split divides leaves into two partitions. If we arbitrarily label these partitions ‘A’ and ‘B’, and select a leaf at random, we can view the partition label associated with the leaf. If 60/100 leaves belong to partition ‘A’, and 40/100 to ‘B’, then the a leaf drawn at random has a 40% chance of bearing the label ‘A’; the split has an entropy of .
Now consider a different split, perhaps in a different tree, that
assigns 50 leaves from ‘A’ to a partition ‘C’, leaving the remaining 10
leaves from ‘A’, along with the 40 from ‘B’, in partition ‘D’. This
split has
of entropy.
Put these together, and a randomly selected leaf may now bear one of
three possible labellings:
- ‘A’ and ‘C’: 50 leaves
- ‘A’ and ‘D’: 10 leaves
- ‘B’ and ‘D’: 40 leaves.
The two splits thus have a joint entropy of .
The joint entropy is less than the sum of the individual entropies because the two splits contain some mutual information: for instance, if a leaf bears the label ‘B’, we can be certain that it will also bear the label ‘D’. The more similar the splits are, and the more they agree in their division of leaves, the more mutual information they will exhibit. I term this the clustering information, in contradistinction to the concept of phylogenetic information discussed above.
More formally, let split divides leaves into two partitions and . The probability that a randomly chosen leaf is in partition is . thus corresponds to a random variable with entropy (Meila, 2007). The joint entropy of two splits, and , corresponds to the entropy of the association matrix of probabilities that a randomly selected leaf belongs to each pair of partitions:
These values can then be substituted into the definitions of mutual information and entropy distance given above.
As and become more different, the disposition of gives less information about the configuration of , and the mutual information decreases accordingly.